



Schema migration can be a real headache, especially in large-scale applications where database structures evolve over time. Traditional methods of schema migration often involve manual intervention, which can be time-consuming, error-prone, and disruptive to ongoing operations. In this article, we will explore how we have eliminated this problem by completely automating the schema migration at our organization with the help of this excellent tool developed by GitHub, gh-ost, which is a triggerless online schema migration solution for MySQL. GH-OST has some requirements and limitations, which we handled separately via our custom rule engine.
GH-OST ??? Who?
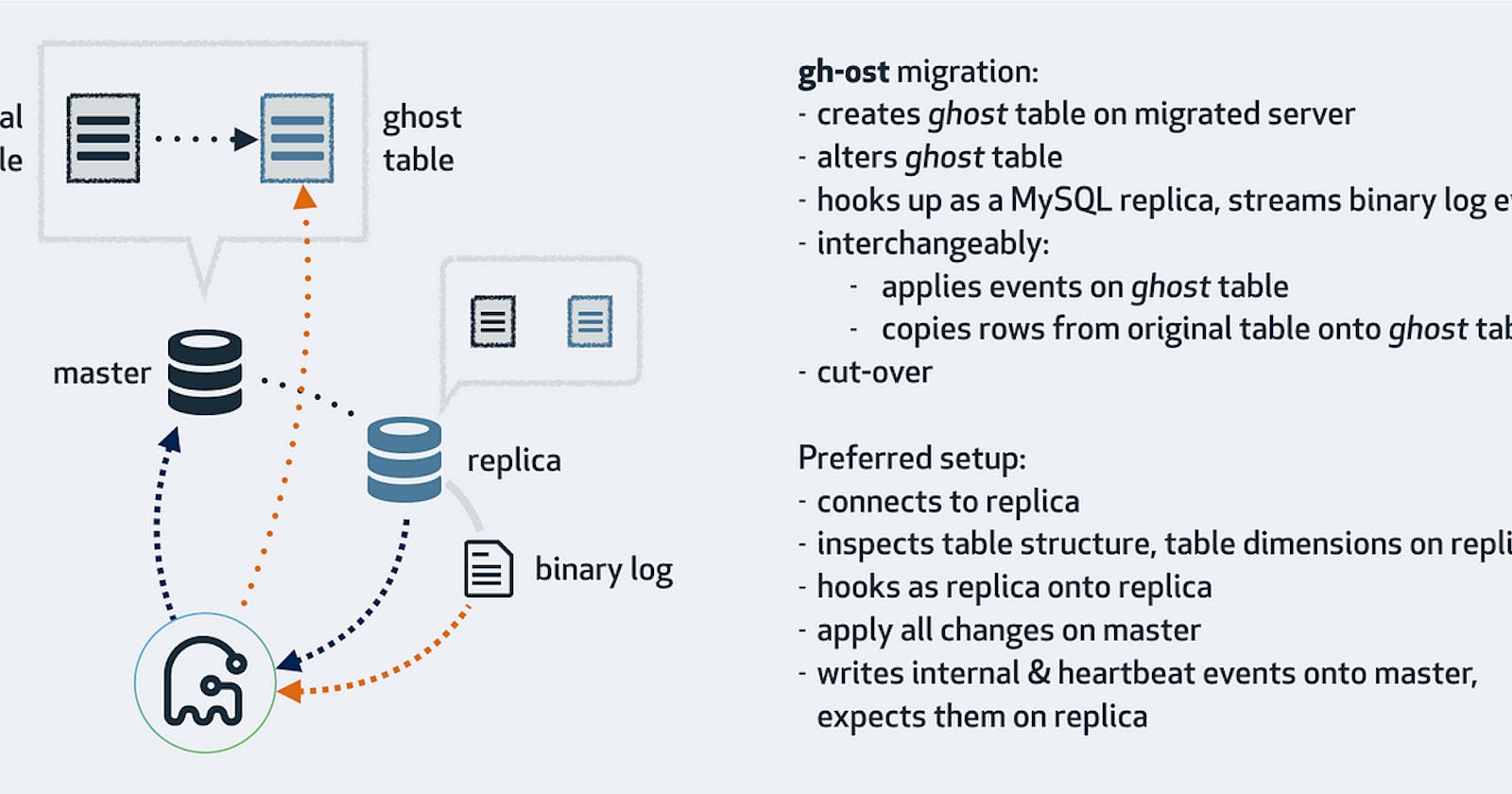
GH-OST operates on a concept similar to other online schema migration tools. It begins by creating a ghost table that closely resembles the structure of the original table. The migration process starts with an empty ghost table, and data is gradually and incrementally copied from the original table to the ghost table. Simultaneously, any ongoing changes, such as INSERT, DELETE, or UPDATE operations applied to the original table, are also propagated to the ghost table. This ensures that the ghost table remains synchronized with the original table throughout the migration process. Finally, when the appropriate moment arrives, GH-OST performs the crucial step (Cut-Over) of replacing the original table with the ghost table, completing the migration seamlessly. This approach allows for minimal downtime and ensures a smooth transition while preserving the integrity of the data. For more detailed information, you can refer to the project description on GH-OST’s GitHub page within the GitHub organization.
The Flow!

In our implementation, we have established a streamlined high-level flow to handle user Alter Requests effectively. When a user initiates an Alter Request, our robust rule engine comes into play, thoroughly examining the submitted details against a predefined set of rules. This ensures that the request aligns with our system’s requirements and standards. Once the request passes the rule checks, it proceeds to the verification stage, where it undergoes scrutiny and approval from project owners, who hold the responsibility of ensuring the request’s validity and feasibility. Following this, the request moves on to the next level of scrutiny, where a database administrator (DBA) thoroughly reviews and approves it, considering the impact on the database environment. Once the request has obtained the necessary approvals, it undergoes execution first in the development or testing environment (DB stage) to ensure smooth implementation and identify any potential issues. Finally, the altered functionality or feature is executed in the production environment, ensuring the changes are reflected for end-users. Throughout this process, all stakeholders involved in the Alter Request are kept informed and notified at each crucial step, maintaining transparency and collaboration. Additionally, to maintain a clean and organized system, a cleanup job is triggered automatically once the process is completed, ensuring any temporary resources or artifacts are appropriately handled. This well-structured flow not only ensures efficient handling of Alter Requests but also emphasizes accountability, reliability, and effective communication among the team members involved.
This was a rough overview of the implemented process; now let’s dive deep into each individual step.
Rule Engine

To facilitate the seamless execution of Alter Requests, we have developed our own rule engine as a Python class, incorporating essential functions to conduct various predefined checks. This rule engine plays a pivotal role in ensuring the integrity and compatibility of the requested changes. Within this engine, a range of checks are performed on both the query and the database environment. Some key checks include verifying the presence of foreign keys in the table, assessing the size of indexes, evaluating the overall database size, examining the size of individual tables, the right time to carry out this migration process, analyzing the maximum thread capacity and current database load, and assessing the status of the database replication.
These checks can be tailored to align with specific organizational requirements, allowing for a customized rule engine that meets the unique needs of our system. By implementing this rule engine, we enhance the accuracy and reliability of our Alter Request process, empowering us to effectively address potential issues and maintain the stability of our database system
Role of our ghostly wizard, GH-OST?

Once the Alter Request has successfully passed the rule engine and undergone the two-step validation process, it enters the realm of our ghostly wizard, GH-OST. Our Python script takes charge at this stage and utilizes GH-OST commands to execute the alteration process seamlessly. The specific GH-OST parameters used in our implementation, which are determined by the rule engine, are outlined below.
Note: {{xyz}} represents variables
1. Test on replica
To ensure a smooth transition, GH-OST performs a test on a replica database before proceeding with the actual alteration.
gh-ost --max-load=Threads_connected={{max_thread_connected}},Threads_running={{max_thread_running}} --cut-over-lock-timeout-seconds=180 --max-lag-millis=50000 --chunk-size=2000 --test-on-replica --throttle-control-replicas={{slave_db_host}}:3306 --port=3306 --user={{username}} --password={{password}} --host={{master_db_host}} --database={{database_name}} --table={{table_name}} --verbose --alter="{{alter_query}}" --switch-to-rbr --cut-over=default --default-retries=120 --nice-ratio=0 --throttle-flag-file={{request_id}}_gh-ost.throttle --postpone-cut-over-flag-file={{request_id}}_ghost.postpone.flag --panic-flag-file={{request_id}}_ghost.panic.flag --execute
2. Execute on master
Once the test on the replica is successfully completed, GH-OST proceeds with the actual execution on the master database.
gh-ost --max-load=Threads_connected={{max_thread_connected}},Threads_running={{max_thread_running}} --cut-over-lock-timeout-seconds=180 --max-lag-millis=50000 --chunk-size=2000 --allow-on-master --throttle-control-replicas={{slave_db_host}}:3306 --port=3306 --user={{username}} --password={{password}} --host={{master_db_host}} --database={{database_name}} --table={{table_name}} --verbose --alter="{{alter_query}}" --switch-to-rbr --cut-over=default --default-retries=120 --nice-ratio=0 --throttle-flag-file={{request_id}}_gh-ost.throttle --postpone-cut-over-flag-file={{request_id}}_ghost.postpone.flag --panic-flag-file={{request_id}}_ghost.panic.flag --execute
The parameters for this phase mirror those used in the replica test, with the addition of the allow-on-master parameter to enable alteration execution on the master database
3. Sanity Check
Before proceeding with the cut-over and finalizing the migration, a sanity check is performed. This check compares the entries in the migrated table and the original table for the past seven days, ensuring a perfect synchronization between the two.
4. Remove postpone file to take cutover and finish migration
Once the migration is ready for the cut-over, the postpone flag file is removed, triggering the swapping of tables and the completion of the migration process.
remove_file = f"{{request_id}}_ghost.postpone.flag"
if os.path.exists(remove_file):
os.remove(remove_file)
logger.info("Cutover flag file removed")
The script checks for the existence of the flag file (postpone-cut-over-flag-file) and removes it if present, allowing the cut-over call to be made and finalizing the migration.
Post Completion

Upon the successful completion of the migration process, the stakeholders involved are promptly notified to acknowledge the accomplishment. However, in the rare event that issues arise during the process, appropriate measures are in place to address them effectively. In such cases, notifications are triggered, employing various communication channels such as Slack, email, or even phone calls to alert the Database Administrators (DBAs) of any errors based on their severity level. This proactive approach ensures that immediate attention is given to high severity errors, enabling swift resolution and minimizing any potential impact on the system. By incorporating robust error handling and notification mechanisms, we reinforce the reliability and resilience of our Alter Request process, fostering a culture of accountability, and ensuring the smooth operation of our database environment.
By implementing this approach, we have significantly alleviated the workload of our DBAs, allowing them to focus their valuable time and expertise on driving innovation and further advancements. To put it into perspective, our system has successfully processed over 10,000 DB requests in the past six months alone. This impressive accomplishment stands as a motivation to our team to consistently deliver timely and reliable innovative solutions while promoting a culture of continuous improvement.